Moogsoft automates the process of making sense out of the real-time events streams generated by IT environments. But for an increasing number of larger enterprise IT and service provider environments, a truly massive amount of event data is created. Moreover, for a variety of reasons, there are often multiple applications (beyond Moogsoft) that consume all or part of these streams. How can this all scale for a large IT environment? Enter Kafka, the open source message broker.
In this post, we’ll explain the basics of Kafka, how it works and why it’s growing in popularity over other publish-subscribe messaging systems. We’ll then summarize a few of the interesting places where Kafka is getting used in monitoring architectures – both virtualized telco SDN/NFV and web scale enterprise environments – and explain how Moogsoft elegantly interfaces with Kafka.
A Basic Understanding of Kafka
While Kafka was originally developed at Linkedln, it is now an open-source technology under the Apache license. Apache Kafka is used as a general-purpose messaging system that is designed to be fast, scalable and durable. The general Kafka use cases include: stream processing, website activity tracking, metrics collection and monitoring and log aggregation.
Apache Kafka is regularly used in the instances mentioned above because it provides:
- Scalability – Distributed messaging system that scales easily without downtime
- Durability – Persists messages on disk, as well as provides intra-cluster replication
- Reliability – Replicates data, supports multiple consumers and automatically balances consumers in case of failure
- Performance – High throughput for both publishing and subscribing
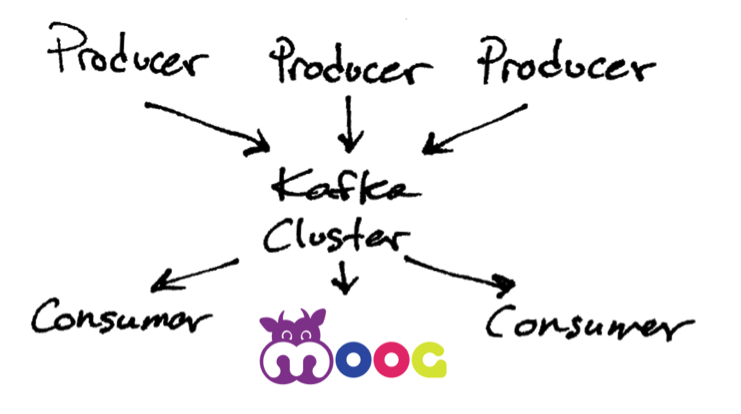
Like other publish-subscribe messaging systems, Kafka maintains feeds of messages in topics. Topics are partitioned and replicated across multiple nodes. Producers (anyone who can publish a message to a topic) write data to topics and consumers (subscribers to one or more topics) read from these topics.
A topic is a user-defined category in which messages are published. Kafka producers can publish messages to multiple topics, while consumers subscribe to these topics and process the published messages. All of this works by producers sending messages over the network to the Kafka cluster, which then turns them over to consumers. A Kafka cluster consists of one or more servers known as ‘Brokers’ that manage the replication of message data.
Same, Same, But Different
What sets Kafka apart from other open-source message broker systems? Traditionally, message brokers have offered a specific set of functions: decoupling the integration complexity from applications that need to use and share data with many other applications, and buffering unprocessed messages in order to ensure that no message is lost. A lot more is possible with Kafka, however.
Sure, Kafka can be used in the traditional way – publishers send messages (topics) to a Kafka cluster (the link between publishers and subscribers), allowing subscribers to choose which topics to receive. Yet the Kafka approach is more efficient than the traditional approaches. Previously, publishers would send data to every single subscriber, resulting in subscribers receiving irrelevant or non-useful information. Kafka performs differently.
Kafka: The Reddit of Application-to-Application Sharing
Consider this comparison: on a very basic level, Kafka is similar to Reddit in that it achieves application-to-application information sharing in the same way Reddit provides human-to-human information sharing. For example, Reddit acts as a real-world message broker by allowing users to choose what topics they wish to see. In particular, Reddit allows users to subscribe to ‘subreddits,’ allowing subscribers to view content only related to the topic of that particular subreddit. Anyone can submit content to the subreddit, as long as it is relevant to the topic and follows the rules.
Reddit and Kafka are similar in that both act as a mechanism for the transportation of information, while also allowing enrichment of information and categorization across multiple topics. This extra bit of secret sauce gives Kafka significant advantages over traditional pub-sub approaches. Kafka goes further than traditional message brokers by running an application that can process data, so that it can be connected to multiple topics. Similarly, Reddit posts can be ‘cross-posted’ between multiple subreddits (topics).
Topics are then broken up into partitions, which are simply ordered sequences of messages – a record of transactions. Each message is assigned a sequential ID number called the ‘offset,’ which can be used to search for the message within a predetermined time period.
It is for these reasons that if you use Kafka to broker your telemetry message data (e.g. app logs, SNMP, syslog, alerts from monitoring tools like New Relic & AppDynamics, etc.), than you have the ability to achieve some very useful functions that are simply not available with traditional data aggregation approaches, including ELK or Splunk.
Kafka Use Cases for Monitoring-at-Scale
Due to Kafka’s unique capabilities, this technology is gaining momentum in emerging telco SDN/NFV environments as a key component for an overall intelligent monitoring architecture. Real-time telemetry – events, alerts, log entries – are generated by all the building blocks of the overall SDN/NFV system: the VIM, VNFM, NFVO, NFVI, VNF catalogs, NFV instances, EM, sub-system monitors, to name a few. Kafka’s scalability, data partitioning, low latency and the ability to handle a number of diverse consumers makes it a perfect fit for large, virtualized telco environments. Furthermore, Kafka’s ability to process millions of messages per second has “telco scale” for the producer of real-time data to write messages into the Kafka cluster, allowing real-time data consumers to read the messages.
Kafka is also ideal for web-scale enterprises. Consider this scenario: Say we are developing a multiplayer online game, where players communicate and operate within a virtual world. Players will often trade game items with each other, so trades must be flagged to ensure that players do not cheat. Real-time event flagging is necessary in this instance, and the best decisions are based on data that is cached on the game server memory (keep in mind the system has multiple game servers).
In order to effectively flag events in real-time, the game servers must accept user actions and process trade information in real-time to flag suspicious events. To process this information in real-time, however, it’s best to have the history of trade events for each user to reside in memory of a single server – this is where Kafka comes in. Kafka allows us to pass messages between multiple servers, while maintaining order within a topic.
Now, when a user logs in or makes a trade, the accepting server immediately sends the event into Kafka. Messages are then sent to consumers, each of which are part of the same topic group. All the data about a specific user arrives to the same event-processing server. Furthermore, when the event-processing server reads a user trade from Kafka, it adds the event to the user’s event history and caches it in local memory, making it easy to flag suspicious events without additional network or disk overhead. Kafka is extremely useful in this instance due to its high throughput and low latency. Kafka can also process close to a million events per second, making it valuable in virtual environments where big data must be consumed in real-time.
Kafka and Moogsoft Today
How is Moogsoft leveraging Kafka right now? To start, we have an expanding partnership with Cisco. Kafka allows Incident.MOOG to ingest and analyze data coming from Cisco’s software applications. Upon receiving these data streams, Incident.MOOG uses its machine learning algorithms to correlate alerts in real-time, determining the full narrative of service-impacting incidents. Various Cisco teams use this data to gain full 360-degree situational awareness across their entire application production stack, so they can catch and resolve service impacting incidents before customers are affected. Kafka also enables applications like Moogsoft to publish ‘enriched data’ back onto Kafka for the advantage of other application subscribers.
One use case is a Cisco virtual CPE solution across an SDN/NFV framework. Moogsoft ingests real-time event streams from the various Cisco components through its Kafka LAM, and provides the service assurance layer for this Cisco offering. Along with Moogsoft, other applications like SevOne and Ontology consume messages relevant to their specific use cases, with data published in a friendly format using the single ingress (Kafka) adapter.
In another use case, Cisco IT is aggregating messages from several of its own production applications (ESC and NSO), along with third party applications (Nagios, Logstash, etc.). Kafka enables these Cisco’s applications to be distributed across the network, while also allowing third party applications (like Moogsoft) to also consume those applications’ messages without increasing the workload on those applications, or having to provide custom integrations.
What’s Next with Moogsoft and Kafka
Kafka helps large IT environments to scale operations, whether it’s a telco SDN/NFV environment or a web-scale enterprise IT environment. The use cases described above are Cisco related, but we see expanding interest in Kafka from our larger customers as well. This is why we support Kafka now, and we expect this new and unique integration will continue to expand Moogsoft’s deployments in some of the largest enterprises and service providers worldwide.



